Let’s start by importing some data into R. Because R is what is called an object-oriented programming language, we’ll always take our information and give it a home inside a named object. There are many different kinds of objects, which you can specify, but usually R will assign a type that seems to fit best.
If you’d like to explore this all in a bit more depth, you can find a very helpful summary in R for Data Science, chapter 8, “data import”.
In the example below, we’re going to read in data from a comma separated value file (“csv”) which has rows of information on separate lines in a text file with each column separated by a comma. This is one of the standard plain text file formats. R has a function you can use to import this efficiently called “read.csv”. Each line of code in R usually starts with the object, and then follows with instructions on what we’re going to put inside it, where that comes from, and how to format it:
setwd("/Users/kidwellj/gits/hacking_religion_textbook/hacking_religion")library(here) # much better way to manage working paths in R across multiple instances
here() starts at /Users/kidwellj/gits/hacking_religion_textbook
library(tidyverse)
-- Attaching core tidyverse packages ------------------------ tidyverse 2.0.0 --
v dplyr 1.1.3 v readr 2.1.4
v forcats 1.0.0 v stringr 1.5.0
v ggplot2 3.4.3 v tibble 3.2.1
v lubridate 1.9.3 v tidyr 1.3.0
v purrr 1.0.2
-- Conflicts ------------------------------------------ tidyverse_conflicts() --
x dplyr::filter() masks stats::filter()
x dplyr::lag() masks stats::lag()
i Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
here::i_am("chapter_1.qmd")
here() starts at /Users/kidwellj/gits/hacking_religion_textbook/hacking_religion
What’s in the table? You can take a quick look at either the top of the data frame, or the bottom using one of the following commands:
head(uk_census_2021_religion)
geography total no_religion christian buddhist hindu jewish
1 North East 2647012 1058122 1343948 7026 10924 4389
2 North West 7417397 2419624 3895779 23028 49749 33285
3 Yorkshire and The Humber 5480774 2161185 2461519 15803 29243 9355
4 East Midlands 4880054 1950354 2214151 14521 120345 4313
5 West Midlands 5950756 1955003 2770559 18804 88116 4394
6 East 6335072 2544509 2955071 26814 86631 42012
muslim sikh other no_response
1 72102 7206 9950 133345
2 563105 11862 28103 392862
3 442533 24034 23618 313484
4 210766 53950 24813 286841
5 569963 172398 31805 339714
6 234744 24284 36380 384627
This is actually a fairly ugly table, so I’ll use an R tool called kable to give you prettier tables in the future, like this:
knitr::kable(head(uk_census_2021_religion))
geography
total
no_religion
christian
buddhist
hindu
jewish
muslim
sikh
other
no_response
North East
2647012
1058122
1343948
7026
10924
4389
72102
7206
9950
133345
North West
7417397
2419624
3895779
23028
49749
33285
563105
11862
28103
392862
Yorkshire and The Humber
5480774
2161185
2461519
15803
29243
9355
442533
24034
23618
313484
East Midlands
4880054
1950354
2214151
14521
120345
4313
210766
53950
24813
286841
West Midlands
5950756
1955003
2770559
18804
88116
4394
569963
172398
31805
339714
East
6335072
2544509
2955071
26814
86631
42012
234744
24284
36380
384627
You can see how I’ve nested the previous command inside the kable command. For reference, in some cases when you’re working with really complex scripts with many different libraries and functions, they may end up with functions that have the same name. You can specify the library where the function is meant to come from by preceding it with :: as we’ve done knitr:: above. The same kind of output can be gotten using tail:
knitr::kable(tail(uk_census_2021_religion))
geography
total
no_religion
christian
buddhist
hindu
jewish
muslim
sikh
other
no_response
5
West Midlands
5950756
1955003
2770559
18804
88116
4394
569963
172398
31805
339714
6
East
6335072
2544509
2955071
26814
86631
42012
234744
24284
36380
384627
7
London
8799728
2380404
3577681
77425
453034
145466
1318754
144543
86759
615662
8
South East
9278068
3733094
4313319
54433
154748
18682
309067
74348
54098
566279
9
South West
5701186
2513369
2635872
24579
27746
7387
80152
7465
36884
367732
10
Wales
3107494
1446398
1354773
10075
12242
2044
66947
4048
15926
195041
2.1.2 Parsing and Exploring your data
The first thing you’re going to want to do is to take a smaller subset of a large data set, either by filtering out certain columns or rows. Now let’s say we want to just work with the data from the West Midlands, and we’d like to omit some of the columns. We can choose a specific range of columns using select, like this:
You can use the filter command to do this. To give an example, filter can pick a single row in the following way:
Now we’ll use select in a different way to narrow our data to specific columns that are needed (no totals!).
Some readers will want to pause here and check out Hadley Wickham’s “R For Data Science” book, in the section, “Data visualisation” to get a fuller explanation of how to explore your data.
In keeping with my goal to demonstrate data science through examples, we’re going to move on to producing some snappy looking charts for this data.
2.2 Making your first chart
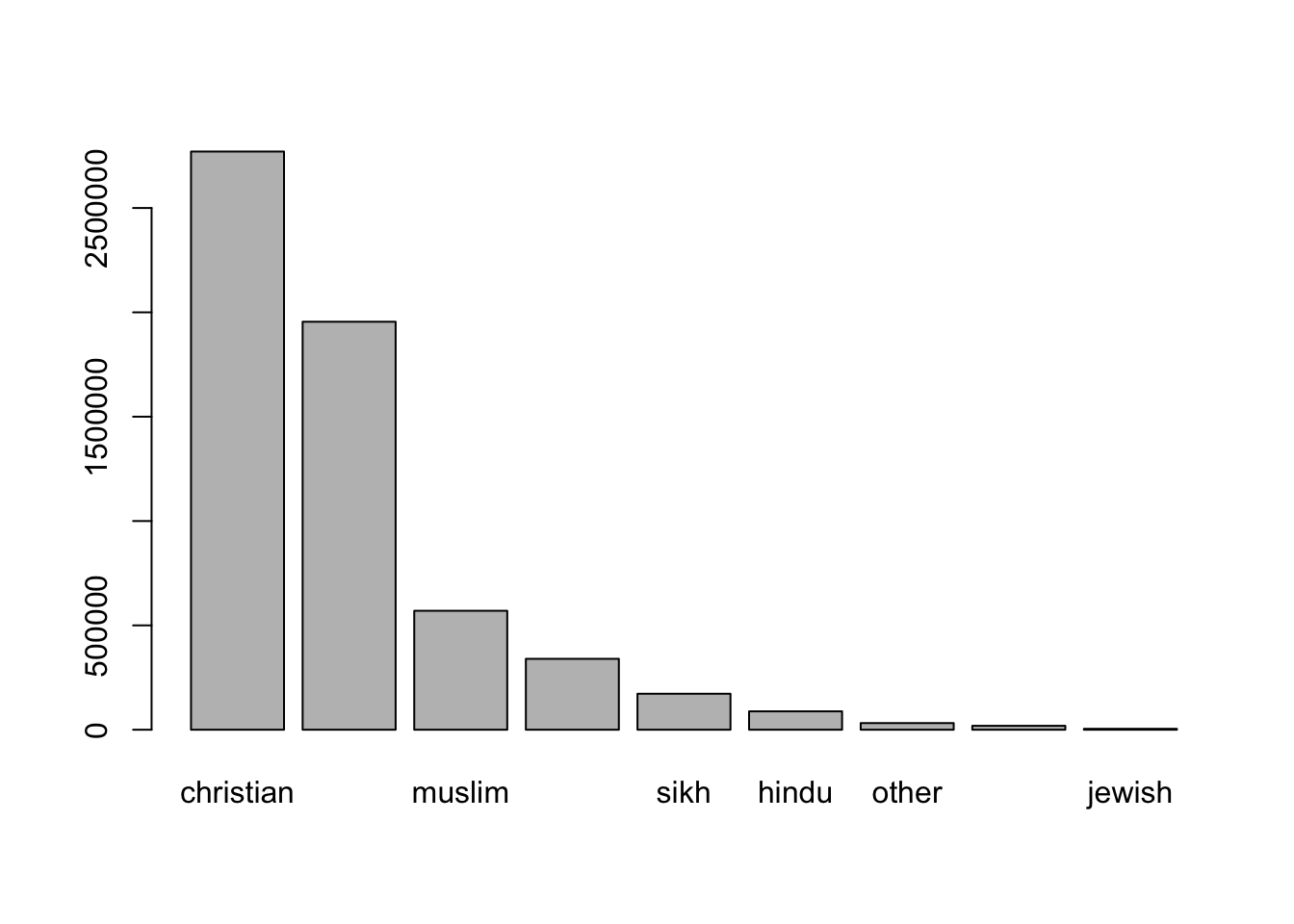
We’ve got a nice lean set of data, so now it’s time to visualise this. We’ll start by making a pie chart:
There are two basic ways to do visualisations in R. You can work with basic functions in R, often called “base R” or you can work with an alternative library called ggplot:
Let’s assume we’re working with a data set that doesn’t include a “totals” column and that we might want to get sums for each column. This is pretty easy to do in R:
First, remove the column with region names and the totals for the regions as we want just integer data.
2
Second calculate the totals. In this example we use the tidyverse library dplyr(), but you can also do this using base R with colsums() like this: uk_census_2021_religion_totals <- colSums(uk_census_2021_religion_totals, na.rm = TRUE). The downside with base R is that you’ll also need to convert the result into a dataframe for ggplot like this: uk_census_2021_religion_totals <- as.data.frame(uk_census_2021_religion_totals)
3
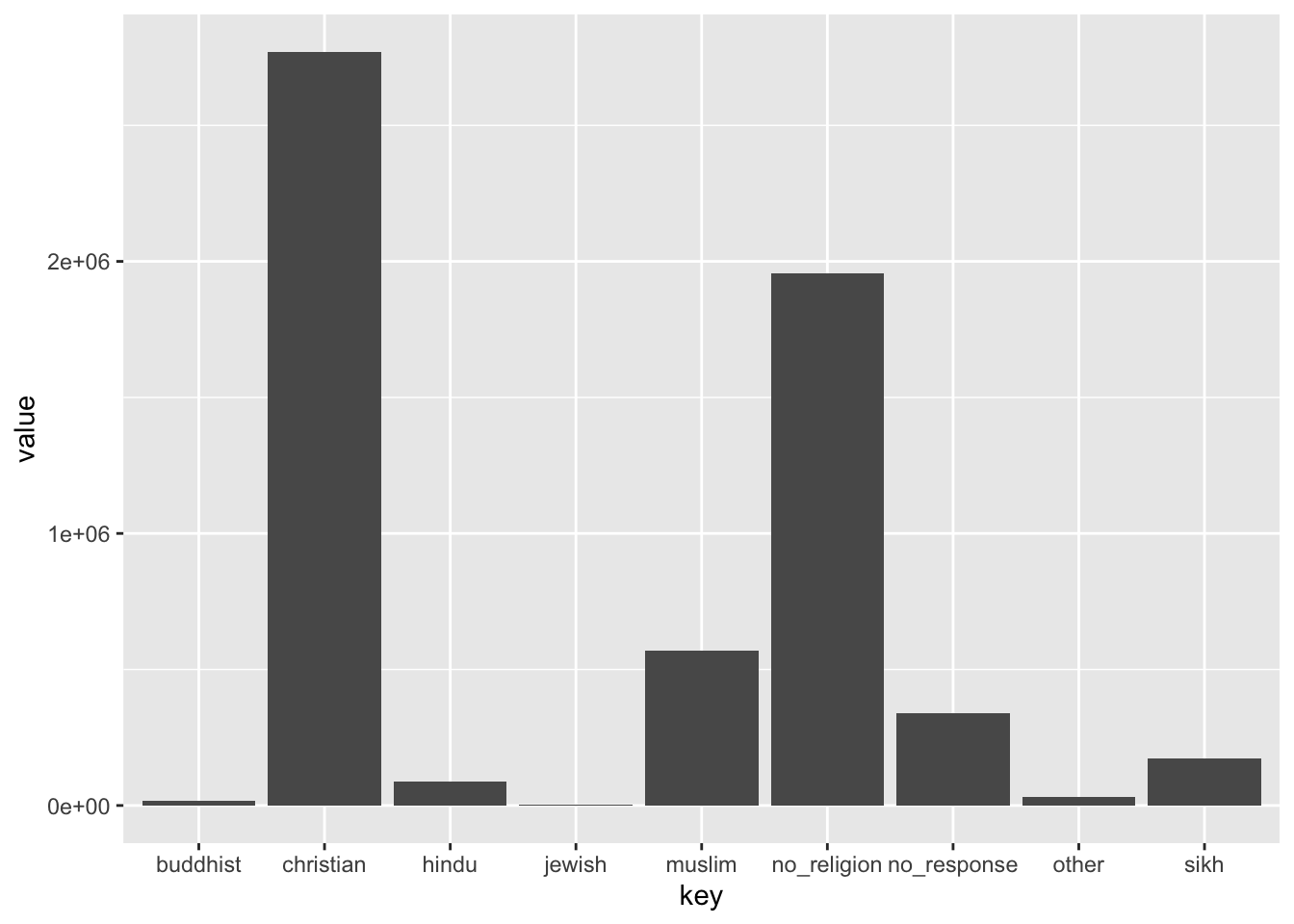
In order to visualise this data using ggplot, we need to shift this data from wide to long format. This is a quick job using gather()
4
Now plot it out and have a look!
You might have noticed that these two dataframes give us somewhat different results. But with data science, it’s much more interesting to compare these two side-by-side in a visualisation. We can join these two dataframes and plot the bars side by side using bind() - which can be done by columns with cbind() and rows using rbind():
Do you notice there’s going to be a problem here? How can we tell one set from the other? We need to add in something idenfiable first! This isn’t too hard to do as we can simply create a new column for each with identifiable information before we bind them:
Now we’re ready to plot out our data as a grouped barplot:
ggplot(uk_census_2021_religion_merged, aes(fill=dataset, x=reorder(key,-value), value)) +geom_bar(position="dodge", stat ="identity")
If you’re looking closely, you will notice that I’ve added two elements to our previous ggplot. I’ve asked ggplot to fill in the columns with reference to the dataset column we’ve just created. Then I’ve also asked ggplot to alter the position="dodge" which places bars side by side rather than stacked on top of one another. You can give it a try without this instruction to see how this works. We will use stacked bars in a later chapter, so remember this feature.
If you inspect our chart, you can see that we’re getting closer, but it’s not really that helpful to compare the totals. What we need to do is get percentages that can be compared side by side. This is easy to do using another dplyr feature mutate: